Architecture of the Language Component
FASTY's core functionality will be provided by a statistic language model based on n-grams. These statistics will be collected not only from standard corpora, but also from texts generated by disabled users in various communication scenarios. In addition, the use of topic specific lexica and word statistics will have to be considered. It is a well known fact, that word probability is not independent of context. Word n-grams yield only a rough approximation of this variation, there are also lexico-semantic and topic- specific factors influencing word distribution. So-called 'recency' adjustment is a special case of this phenomenon. Different approaches, such as collocation analysis or trigger pair identification will be explored to collect statistics that may help in finding the most probable predictions. The use of these statistics and their integration in a prediction system is another innovative aspect of the FASTY system.
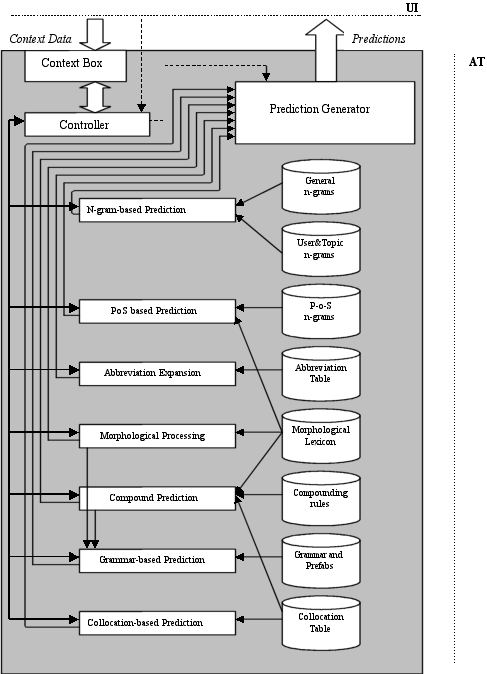
The variety of languages to be supported and methods to be integrated into the FASTY system demands a modular architecture. The combination and integration of prediction components needs to be handled in a very flexible way, for a variety of reasons:
Thus the backbone of the linguistic prediction component of the FASTY system will be a controller that is flexibly driving the different prediction modules and combining their results. Thus it will be easy to optimise the overall prediction behaviour and also adaptation of FASTY to another language without modifying the whole system will be made possible.
When one considers methods for saving keystrokes in text typing, one has to differentiate between keystroke-saving methods in the UI and methods involving linguistic or statistical prediction of words, word sequences and phrases. Here we will put our emphasis on the latter. However, for the sake of completeness a short listing of methods belonging to the User Interface side will be given.
All systems on the market that we are aware of use some kind of frequency statistics on words and (sometimes) word combinations. Given a prefix of a word, with a frequency annotated lexicon the most probable continuation(s) of that word can be retrieved easily. Sometimes, not only word-based frequency counts are maintained (1-grams), but also bigrams and even trigrams are used for enhancing prediction accuracy. N-gram language models are widely used in speech recognition systems, and their benefits are also exploited in some predictive typing systems. The key observation behind this kind of models is, that the probability of a word occurring in the text depends on the context.
The superiority of n-gram based predictions over simple frequency lexicons stems from the fact, that n-grams are able to capture some of the syntactic and semantic regularities intrinsic to language. However, a severe drawback of word- based n-grams is, that, even with very large training texts, the data still is rather sparse, and thus in many actual cases during prediction no information is available. The usual technique to cope with syntactic regularities uses class- based n-grams (usually n=3), the classes being defined by the part-of-speech information of a tagged corpus. Copestake reports on an improvement in KSR of 2.7 percent points by just taking PoS-bigrams into account. A good description on the integration of PoS trigrams into a statistical word prediction system for Swedish is given in.
For a human language user it is obvious that in a given context some words are more probable than others just because of their semantic content. Factors influencing word probability due to semantics are (among others):
Collocation analysis (in a broader sense, not reduced to idioms only) can reveal some of these dependencies. However, very large corpora are needed. Rosenfeld uses the concept of "trigger pairs" to capture these relationships statistically (basically these are bi-grams of words occurring together in a window of a certain size in a corpus). If a word that has been recently entered occurs in such a trigger pair the probability of the other word of the pair should be increased. Recency, as implemented as a heuristic in some prediction systems, can be seen as a self trigger and is a (rather crude) measure to exploit semantic or topical appropriateness of a word.
Several methods of integrating grammar rules into statistics based prediction have been tried, but none of them had made it into a commercially successful product. Such an integration, however, is seen as a major challenge in the FASTY system.
Basic to our approach is the modular architecture of our system. In addition to the flexibility such an approach provides for the adaptation to different languages, application scenarios and users - as described in the introduction - it also ensures robustness and graceful degradation in the case one module should be missing or fail. Furthermore, this type of architecture allows for the possibility of exploring various more advanced - and albeit more risky - methods without endangering the successful implementation of the language component in case some of these methods should not prove successful.
The core of the system will be a module based on the prediction of word forms due to their absolute frequency and the probability of their associated PoS. Such a module is state-of-the-art and guarantees a basic performance. A number of other methods to improve prediction quality will be investigated. All methods will be evaluated with respect to their performance for different target languages and language specific phenomena (e.g., compounding). Those that prove to be successful for one or more of the target languages will be integrated with the core component - either alone or in combination with others.
As mentioned previously, n-gram prediction (for n > 1) is superior to the use of a simple frequency-ranked lexicon, and will be used in the FASTY language model as a base. The probability of occurrence of a list of word bigrams will be the main reference since it is expected to contribute most to the appropriate choice of predicted items. Word n-grams of longer lengths, including so-called lexicalised phrases, will also be taken into account. Because most word n-grams for n > 2 have low probability in comparison to word bigrams, methods will be developed to ascertain when and how to predict them. These word n-grams will be accessed for both word prediction, when a complete word is chosen to follow an already-typed word, and for word completion, when the user has already begun to type a word. Text corpora for the acquisition of word n-grams will be collected from material belonging to the project partners and from texts on the Internet that are freely available for use.
If the probabilities of user- and topic-specific words are to be consistent with the probabilities of the word n-grams which are derived from corpora containing millions of words, the texts from which these words are taken would have to be of the same order. Since this is not possible, especially in the case of user-specific words, a factor to adapt the measured probability of words and longer expressions in the user- and topic-specific lexicons will be determined by experimentation. It will be possible to generate lexicons of both user- specific and topic-specific words and expressions from previously written, and electronically readable, texts. User-specific words and expressions will also be stored during text composition. The use of several user- and topic-specific lexicons at the same time will be allowed and all activated lexicons will be searched. Words and expressions with highest probabilities (naturally occurring as in the case of word bigrams, or adjusted as in the case of longer expressions and words coming from user- and topic-specific lexicons) will be offered in a prediction list.
User-specific word n-grams may be collected automatically by the word prediction program while the user is writing texts. They may also be included in the database by generating entries from previously-written texts while running the program in an automatic mode. This same method may be used for any computer- available texts in particular subject areas.
A statistical model will be devised in which probabilities for tag trigrams play an important role. A factor determining the relative importance of this information will be derived experimentally. Tagged text corpora or previously developed taggers will be acquired from researchers or research institutions for the acquisition of word class n-grams where this is found to be possible.
The morphological component has three modes of operation:
Morphological processing will be implemented with finite-state transducers. A prototype implementation is already available as an ÖFAI background resource. How the needed large coverage morphological lexica will be acquired is not yet clear. Several possibilities exist: one could start from wordlists either given or collected from corpora and use existing morphology engines to come up with the analysis of these words. Another way could be a learning approach. The resulting annotated wordlist can then be converted into a transducer.
The following basic functionality should be foreseen:
Abbreviations are entered by the user or by its care-person. The possibility of automatically scanning the user's texts for frequently occurring word combinations and suggesting abbreviation codes for them can be explored.
Collocation-based prediction should deliver a list of correlated words given a list of content words (from a fixed window of the left context). Input as well as output will be lemma-based, as morphological variation is supposed not to contribute significantly to the semantic relation, and lemma-based counts will be less sparse. Consequently, the collocation component will have to interact with the morphological processor.
Trigger pairs will have to be collected from rather large corpora, which need not have any annotation. Morphological analysis will be needed during collection, since the triggers should be lemma-based. A publicly available tool for efficiently extracting trigger pairs from large corpora has been written by Adam Berger and can be downloaded from http://www.cs.cmu.edu/~aberger/software/.
The syntactic predictions will be based on partial parsing. The grammar will not be complete. It will include rules for selected constructions that are identified as crucial from a prediction point of view for the individual languages of the projects. Typically, they will be constructions with a fairly fixed word order and feature constraints. Examples of such constructions are nominal phrases, prepositional phrases, and verbal clusters. Sentence initial position and the placement of the finite verb are candidates for additional focal points considered by the grammar. The grammar-based predictions will be scored according to frequency, internal syntactic structure, and, if appropriate, the position of the phrase in the sentence. In terms of these scores, the predictions generated by the syntactic component will compete with those generated by the other modules of the system. Sometimes, they will coincide.
It is planned to use the extensive work of the partner at Uppsala University in chart-based grammar checking as a basis for the syntactic component. A concrete result of this work is a chart-based parser for partial parsing written in C. It goes with a grammar for Swedish, but grammars for the other languages of FASTY remain to be written. The parser provides a basis for generating prefabs in terms of syntactic phrases, provided that a full-form dictionary is available. Tools for analysing compounds and other words outside the dictionary will be shared with other components of the system.
Presumably, compound prediction is useful only, if the first part of the compound is already known. The following factors will most probably influence the prediction of compounds:
Taken these factors into account, the component will deliver compound predictions. Morphological compound formation rules have to be taken into account. Since compound prediction is a true innovation in word prediction systems, the way how to infer new compounds from the input evidence is not precisely known yet and subject to further research within the project.
The morphological compound formation rules have to be created manually by language experts, alternatively a learning approach can be explored. Acquisition of the mutual information statistics will be similar (if not identical) to the one needed for collocation-based prediction. In addition, compounds existing in the lexicon will be analysed and contribute also to the mutual information statistics.
The operation of the Language Component is driven by the User Interface. Depending on the request type the LC returns one or more values as a response to the UI (e.g. the n most likely predictions). A central part of the interface between LC and UI is the Context Box. Its most important part is a string buffer serving as a communication area between. It contains he left context of the current text entry point.
The Controller receives requests from the User Interface and is responsible for
Possibly enriching the Context Box with data returned from some components (e.g. part-of-speech information)
The Prediction Generator receives the predictions made by the different components, together with their probabilities, and combines them to a prediction list which is delivered to the User Interface. How the Prediction Generator comes up with the combined prediction depends on
Each of the components relies on language specific resources, some are shared between different components. Also the possibility exists, that a component uses the results of other components, e.g. Grammar-based prediction uses compound analysis and morphological processing.
Speech synthesis can play an important role in a word prediction system. For users who have reading problems including persons with dyslexia, it is very helpful to have words in the prediction list read aloud. These words are very similar after the first letter or two of a word has been typed, and this can be quite confusing for someone who often recognises words just from their first letters. Results that were obtained during the user's survey reported in "Report on user abilities, preferences and needs" confirm this. Users point out that an audible feedback of a selected word is a very attractive option. Nowadays most of the text prediction software on the market include a speech synthesiser. The FASTY system will follow this line. Additional advantages provided by a speech synthesiser can be given by allowing all menu items and messages to be readable by means of speech synthesis. Hereby all users will be able to participate fully in the use of the program.
The speech synthesiser should easily handle several languages and, in the first place, all the project languages. The speech synthesiser that we intend to use will be a combination of a "grapheme (letter) to phoneme" converter and a "phonetiser" (phoneme to sound converter). The "grapheme to phoneme" converter will be based on a so-called induction decision tree. It learns "grapheme to phoneme" conversion rules automatically from a phonetised dictionary. Thus no extra linguistic knowledge need to be generated provided that a large phonetised dictionary is available. This is an important aspect in the multilingual setting of the FASTY project.
The phonetiser that we propose to use in FASTY project is the award winning (IT European award 1996) MBROLA synthesiser available through Multitel partner. MBROLA is a speech synthesizer based on the concatenation of diphones. It takes a list of phonemes as input, together with prosodic information (duration of phonemes and a piecewise linear description of pitch), and produces speech samples that may be played in the earphone of the computer. More information on MBROLA synthesiser algorithm may be found at http://tcts.fpms.ac.be/synthesis/mbrola. MBROLA currently handles 26 languages and the procedure to add a new one is easy and well defined. Note, however, that not all the languages of the FASTY project are available yet.
The language component delivers a list of predictions to the UI and the UI transfers them to the speech synthesiser to be played by the earphone. The predictions must be supplied with information about part of speech for the speech synthesis to work well. The speech module should drive any sound card compatible with Microsoft Windows standards.